In 2011, am citit un post pe Moz, intitulat “Treziti-va, experti SEO! Noul Google este aici!”
In respectivul articol se prezinta cateva concepte carora, in opinia mea, noi, expertii SEO, trebuie sa le acordam o deosebita atentie pentru a putea urmari evolutia motorului de cautare Google.
Sigur, se prezenta si o teorie care, in cele din urma, s-a dovedit a fi incorecta; am fost mult prea increzator cu privire la lucruri precum rel = “author” (un tag ce indica faptul ca un link este indreptat spre informatii despre autorul unei pagini sau articol; stabileste o relatie intre un document si autorul unui document), rel = “publisher” (un tag care face legatura dintre o pagina de afaceri Google+ si un intreg site, spre deosebire de tag-ul rel=”author”, care revedinca doar un singur articol; face legatura intre site-uri web si pagina Google+ a editorului), precum si potentialul declin al influentei Link Graph.
Cu toate acestea, premisele acestei teorii au fost in mod substantial corecte, lucru valabil si cinci ani mai tarziu:
1. SEO tehnic este fundamental pentru punerea in practica a strategiei de optimizare SEO.
2. Utilizatorul este rege, ceea ce inseamna ca Google se va concentra tot mai mult pe furnizarea celei mai bune experiente de cautare pentru utilizatori – prin urmare, SEO trebuie să evolueze de la “Search Engine Optimization” (Optimizarea motoarelor de cautare) la “Search Experience Optimization” (Optimizarea experientei de cautare).
3. Optimizarea performantei web (SiteSpeed), 10x content (continut care este de 10 ori mai bun decat cel mai bun rezultat afisat pe pagina cu rezultatele cautarii pentru un anumit cuvant cheie, o anumita fraza sau un anumit subiect) si semantica ar fi jucat un rol important in SEO.
Multe lucruri s-au schimbat in industria noastra in ultimii 5 ani. A venit timpul sa punem pauza, sa reflectam cateva minute, sa evaluam ce este Google si incotro se indreapta.
Voi explica modul in care “studiez” Google dar si care consider cu tarie ca sunt chestiunile carora noi, expertii SEO, ar trebui sa le acordam o atentie deosebita daca vrem nu numai sa supravietuim, ci si sa anticipam ultimul stadiu al motorului de cautare Google, pregatindu-ne pentru ce va urma.
Explorarea universului extins al Google

SEO este un taram al incerditudinii.
Cu toate acestea, exista o constanta care nu se schimba niciodata: aproape toti expertii SEO viseaza sa fie cavaleri Jedi cel putin o data in viata.
Si eu am fantezii in legatura cu utilizarea Fortei… Gianluca Fiorelli, Maestru Jedi.
Desi, sincer, cred ca ma aseman mai mult cu Mon Mothma.
Ca si ea, eu sunt un strateg prin natura mea. Imi place sa investighez, sa vad conexiunile acolo unde nimeni altcineva nu pare sa le vada si sa sap mai adanc pentru a gasi raspunsuri la intrebari complexe, apoi sa pun la punct planuri bazate pe investigatiile mele.
Acest fel de a fi inseamna ca, atunci cand ma uit la misterioasa gaura de vierme care este Google, examinez mai multe surse:
1. Blogurile oficiale Google;
2. Hangout-urile “Office Hours”;
3. Declaratiile uneori contradictorii pe care angajatii Google le fac pe retelele sociale (atunci cand nu partajeaza o bucla infinita de GIF-uri);
4. Brevetele Google si cele depuse de catre persoanele care nu lucreaza pentru Google;
5. Stirile (si povestile) despre companiile pe care Google le achizitioneaza;
6. Biografiile oamenilor pe care Google ii angajeaza in domenii cheie;
7. Loialitatea fanilor Google (adica ceea ce scriem despre acest motor de cautare);
8. Zvonurile si propaganda.
Acum, examinand toate aceste surse, este usor sa creezi teorii conspiranoice (conspiratie + paranoia). Si marturisesc: am ajutat la crearea unora dintre ele, am crezut si sustinut unele dintre ele, cum ar fi AuthorRank.
In opinia mea, insa, aceasta metodologie de gasire a raspunsurilor despre Google este cea mai buna pentru a intelege viitorul iubitei noastre industrii de cautare.
Daca nu vom sapa in “Universul Extins al Google”, ceea ce avem este o cronologie compusa numai din actualizari (Panda 1.N, Penguin 1.N, Pigeon…), care este total inutila pe termen lung: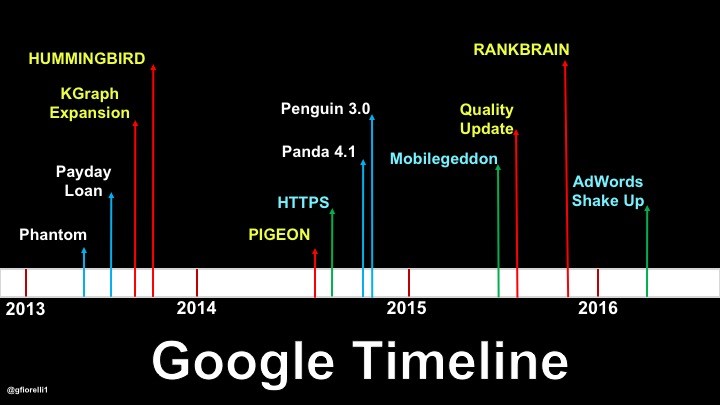
Daca. in schimb, cream un calendar cu toate evenimentele legate de Google Search (pe care le putem descoperi cu usurinta daca suntem bine informati), incepem sa vedem incotro se indreapta Google.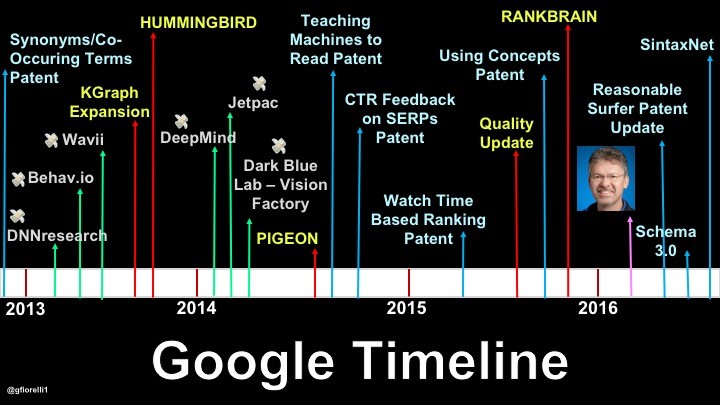
Cronologia de mai sus confirma ceea ce compania Google insasi a declarat in mod deschis:
“Invatarea automata (machine learning) este o modalitate esentiala si transformationala prin care regandim cum facem totul.” (Sundar Pichai)
Google devine o “companie care aplica tehnicile machine learning”, dupa cum este definita de catre Steven Levy.
Machine learning (un subdomeniu al stiintei calculatoarelor, care a evoluat de la studiul recunoasterii formelor si studiul teoriei invatarii automate in inteligenta artificiala) devine atat de esentiala in evolutia Google si in evolutia procesului de cautare. Poate ca ar fi bine sa nu ne limitam doar la a asculta purtatorii de cuvant oficiali ai companiei Google, cum ar fi Gary Illyes sau John Mueller (nu e nimic personal).
Poate ca ar trebui sa luam in considerare ceea ce scriu si spun oameni precum Christine Robson, Greg Corrado, Jeff Dean, dar si membrii echipei Google Brain.
Cea de-a doua cronologie ne spune ca, incepand din 2013, Google a inceput sa investeasca in mod constant bani, eforturi intelectuale si energie in:
• Invatare automata;
• Semantica;
• Intelegerea contextelor;
• Comportamentul utilizatorului (sau “Semnale / semiotica”, asa cum imi place mie sa-l numesc).
2013: Anul in care totul s-a schimbat
Google a lansat Hummingbird in urma cu doar trei ani, insa este ca si cum acest update de algoritm a fost lansat acum zeci de ani.
Sa facem o scurta trecere in revista: ce este Hummingbird?
Hummingbird este algoritmul Google, in ansamblul sau. Este compus din patru faze sau etape:
1. Accesarea cu crawlere, care colecteaza informatii de pe web;
2. Parsing (parsarea), care identifica tipul de informatii colectate, il sorteaza si il transmite unui destinatar corespunzator;
3. Indexarea, care identifica si asociaza resursele asociate cu un cuvant si / sau cu o fraza;
4. Cautarea, care:
o Intelege interogarile utilizatorilor;
o Extrage informatii referitoare la interogari;
o Filtreaza si grupeaza informatiile extrase;
o Claseaza resursele;
o Umple pagina cu rezultatele cautarii, raspunzand, astfel, interogarilor.
In aceasta ultima faza, Cautarea, gasim cei “200+ factori de ranking Google” (200 de factori care influenteaza pozitia site-ului in Google), inclusiv RankBrain, si filtre precum sau algoritmi anti-spam, cum ar fi Penguin.
Este important de mentionat faptul ca exista atatea faze de cautare cat indicatori verticali (documente, imagini, stiri, video, aplicatii, carti, harti…)
Noi, expertii SEO, tindem sa ne axam aproape in exclusivitate pe faza cautarii, uitand ca Hummingbird este mai mult decat atat.
Aceasta abordare a Google este mioapa si nu rezista exercitiului patratului logic.
1. Daca Google este capabil sa acceseze corect cu crawlere un site web (Crawling);
2. Sa-i inteleaga sensul (Parsare si indexare);
3. si, in cele din urma, daca site-ul in sine raspunde in mod pozitiv numerosilor factori care influenteaza pozitia site-ului in Google – factori de ranking (Cautare);
4. Atunci, respectivul website va castiga vizibilitatea organica la care si-a propus sa ajunga.
Daca macar unul dintre cele trei elemente ale patratului logic lipseste, lipseste si vizibilitatea organica; ganditi-va la site-urile web non-optimizate AngularJS si veti intelege logica.
Cum putem fi Jedi SEO daca vedem doar o fateta, un aspect al Fortei?
Parsarea si indexarea, adesea uitate
Pe parcursul ultimelor 18 luni, am asistat la o renastere a optimizarii tehnice a motorului de cautare (SEO tehnic), asa cum este definita de catre Mike King in acest articol si in ciuda eforturilor de a clasifica expertii in SEO tehnic ca make-up artisti.
Dimpotriva, inca ne luptam sa intelegem pe deplin importanta fazelor Parsare și Indexare.
Desigur, putem justifica acest lucru afirmand ca parsarea este cea mai complexa dintre cele patru faze. Google este de acord, aaa cum a declarat in mod deschis atunci cand a anuntat lansarea perser-ului (analizatorului) SyntaxNet.
Cu toate acestea, daca nu optimizam pentru procesul de parsare, atunci nu vom beneficia pe deplin de pe urma cautarii organice, mai ales in lunile si anii urmatori.
Cum sa optimizam pentru parsare si indexare
Ca o premisa pentru optimizarea parsarii si indexarii, trebuie sa ne amintim un aspect al procesului de cautare care este deseori uitat si pe care Hummingbird l-a evidentiat si imbunatatit: entity search (cautarea entitatilor).
Daca va amintiti ce a spus Amit Singhal cand a anuntat lansarea Hummingbird, el a declarat ca avea “ceva din Knowledge Graph (Graficul cunostintelor)”.
Acea parte era – si voi simplifica totul, pentru a fi mai clar – cautarea entitatilor, care se bazeaza indeosebi pe doua tipuri de entitati:
1. Entitatile numite definesc tocmai ceea ce reprezinta Knowledge Graph: persoane, obiective turistice, brand-uri, miscari istorice si concepte abstracte, cum ar fi “dragoste” sau “dorinta”;
2. Entitatile de cautare sunt “lucruri” asociate actului de cautare. Google le utilizeaza pentru a determina raspunsul la o interogare, mai ales intr-un context personalizat. Acestea includ:
o Solicitarea / interogarea;
o Documentele si domeniul care raspund solicitarii / interogarii;
o Sesiunea de cautare;
o Texte ancora ale link-urilor (interne sau externe);
o Timpul in care interogarea este executata;
o Anunturile care raspund unei interogari.
De ce este importanta entity search (cautarea entitatilor)?
Este importanta intrucat cautarea entitatilor este motivul pentru care Google intelege mai bine contextul personal si aproape unic al unei interogari.
Mai mult decat atat, datorita cautarii entitatilor, Google intelege mai bine semnificatia documentelor pe care le interpreteaza. Acest lucru inseamna ca are capacitatea de a le indexa mai bine si, in cele din urma, de a-si atinge scopul principal: afisarea celor mai bune raspunsuri la interogarile si solicitarile utilizatorilor.
De aceea este importanta semantica: cautarea semantica reprezinta optimizarea sensului.
Nu este un factor care influenteaza pozitia site-ului in clasamentului rezultatelor cautarii, nu necesita imbunatatirea accesarii cu crawlere, dar este fundamentala pentru Parsare si Indexare, fazele atat de esentiale ale algoritmului, dar mereu uitate de expertii SEO.
Semantica si SEO
In primul rand, trebuie sa luam în considerare faptul ca exista diferite tipuri de semantica si ca, uneori, oamenii au tendinta de a le confunda.
1. Semantica logica, care se refera la relatiile dintre concepte / elemente lingvistice (spre exemplu: referinta, presupozitie, implicare, etc).
2. Semantica lexicala, care se refera la semnificatia cuvintelor si la relatia dintre acestea.
Semantica logica
La ora actuala, datele structurate reprezinta elementul esential in semantica logica, iar Google investeste foarte mult in acest element (atat direct, cat si indirect).
Cu cateva luni in urma, atunci cand gurusphere a dezbatut cele 50 de nuante ale noului logo Instagram sau cand persoanele obisuite care activeaza in domeniul SEO si-au exprimat nemultumirea fata de butonul verde pentru anunturi de pe paginile cu rezultate ale motorului de cautare (si pe buna dreptate), Google a lansat noua versiune a Schema.org.
Aceasta noua versiune, dupa cum Aaron Bradley a caracterizat-o intr-un mod extrem de fin, imbunatateste capacitatea de a face diferenta intre entitati si / sau de a explica mai bine sensul acestora.
De exemplu, acum:
• Putem folosi tipuri si proprietati specifice produsului, precum Brand, Audience sau IsRelatedTo;
• Putem folosi noua proprietate “disambiguatingDescription” pentru a putea face mai bine diferenta intre elementele similare (ganditi-va la numeroasele categorii de produse din domeniul comertului electronic).
• Putem optimiza, in cele din urma, pentru SEO semantic international datorita noului tip Schema.org/ComputerLanguage.
Totodata, nu trebuie sa uitam sa utilizam intotdeauna cea mai importanta proprietate dintre toate: “SameAs”, una dintre putinele proprietati prezenta in fiecare tip Schema.org.
In cele din urma, dupa um Mike Arnesen a explicat recent pe blog-ul Moz, profitati de atributele semantice ale HTML, ItemRef si ItemID.
Cum implementam Schema.org in 2016?
Este clar faptul ca Google recomanda JSON-LD ca metoda preferata pentru punerea in aplicare a Schema.org
Cel mai bun mod de a implementa JSON-LD Schema.org este utilizarea Knowledge Graph Search API, care utilizeaza tipurile standard de Schema.org si este compatibil cu specificatiile JSON-LD.
Ca o alternativa, puteti utiliza recent lansatul instrument JSON-LD Schema Generator pentru SEO, conceput de catre cei de la Hall Analysis.
Pentru a rezolva o problema des invocata cu privire la JSON-LD (volumul sau si modul in care poate afecta performanta unui site), putem:
1. Sa utilizam Tag Manager pentru a declansa Schema.org atunci când este necesar;
2. Sa utilizam PreRender cu scopul de a permite browser-ului sa sa inceapa sa incarce paginile pe care utilizatorii dumneavoastra le pot vizita pornind de la pagina pe care se afla in momentul respectiv, anticipand incarcarea elementelor JSON-LD ale acestor pagini.
Importanta pe care Google o acorda Schema.org si datelor structurate este confirmata de noua versiune radical imbunatatita a instrumentului de testare a datelor structurate (Structured Data Testing Tool), versiune care este mult mai folositoare in identificarea erorilor si solutiilor de testare, multumita sugestiilor sale contextuale de completare automata JSON-LD (din nou!) si Schema.org.
Semantica inseamna mai mult decat date structurate!
In opinia multora, cautarea semantica se refera doar la datele structurate, insa este o conceptie gresita.
Este aceeasi greseala pe care oamenii o fac in SEO international, atunci cand reduc acest concept la etichetele hreflang.
Realitatea este ca semantica este prezenta chiar din bazele un website, fiind gasita in:
1. Codul sau, indeosebi HTML;
2. Arhitectura acestuia.

Inca de la inceputurile sale, HTML a inclus marcajul semantic (ex: titlu, H1, H2…)
Cea mai noua versiune a sa, HTML5, a adaugat noi elemente semantice, al caror scop este acela de a organiza din punct de vedere semantic structura unui document web si, dupa cum spune W3C, de a permite “ca datele sa fie partajate si reutilizate de catre mai multe aplicatii, intreprinderi si comunitati.”
Un exemplu clar al modului in care Google utilizeaza elementele semantice ale HTML il reprezinta “Featured Snippets” (Fragmente relevante – un raspuns extras de pe un site, pe care Google il afiseaza ca un fragment relevant in partea de sus a rezultatelor cautarii) sau casetele de raspunsuri.
Dupa cum insasi compania Google a declarat (“Noi nu folosim date structurate pentru a crea fragmente relevante”) si dupa cum au declarat Dr. Pete, Richard Baxter si, recent, Simon Penson, documentele care tind sa fie folosite pentru casete de raspuns prezinta, de obicei, acesti trei factori:
1. Ele se claseaza deja pe prima pagina a rezultatelor cautarii, afisand, astfel, casuta de raspunsuri.
2. Au un raspuns pozitiv, folosind factori tehnici (elementele din site care pot influenta pozitia in motorul de cautare) fundamentali.
3. Au un cod HTML curat – sau aproape curat.
In acest caz, concluzia este ca mult-discutata cautare semantica incepe din cod si ca ar trebui sa acordam mai multa atentie acelor rapoarte de eroare W3C, pe care mult dintre noi le consideram “plictisitoare”, “consumatoare de timp” sau “neimportante”.
Arhitectura
Semioticianul din mine (am studiat, in universitate, semiotica si filosofia limbajului, cu personalitati asemanatoare lui Umberto Eco) nu poate decat sa sustina cu tarie ca insasi arhitectura de informatii este semantica.
Dati-mi voie sa va explic.
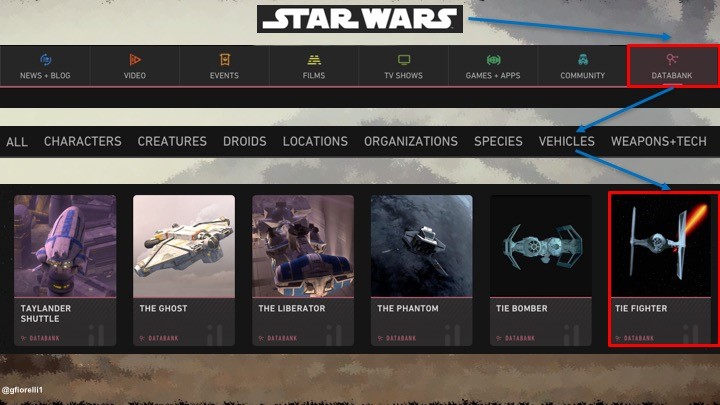
Deschideti http://www.starwars.com/ intr-o fila a browserului dumneavoastra pentru a urmari cele scrise mai jos
Totul incepe cu ontologia corecta
Ontologia reprezinta un set de concepte si categorii dintr-o disciplina (sau domeniu stiintific) care prezinta proprietatile acestora si relatiile dintre ele.
Daca luam ca exemplu site-ul Starwars.com, putem observa, in meniul principal, conceptele din ramurile site-ului Star Wars.
1. Noutati / Blog;
2. Videoclipuri;
3. Evenimente;
4. Filme;
5. Seriale TV;
6. Jocuri / Aplicatii;
7. Comunitate;
8. Banca de date (enciclopedia Star Wars)
Ontologia conduce la taxonomie (pentru ca totul poate fi clasificat)
Daca aruncam o privire pe StarWars.com, vom observa modul in care fiecare concept inclus in domeniul Star Wars are propria sa taxonomie.
De exemplu, DataBank prezinta mai multe categorii, precum:
1. Characters (Personaje);
2. Creatures (Creaturi);
3. Locations (Locatii);
4. Vehicles (Vehicule);
5. Multe altele.
Ontologia si taxonomia conduc, apoi, la context
Daca ne gandim la Tatooine, avem tendinta sa ne gandim la planeta-mama a lui Luke Skywalker, planeta pe care acesta si-a trait tineretea.
Cu toate acestea, daca vom vizita un site despre explorarea mai profunda a spatiului, Tatooine ar fi una dintre multele exoplanete pe care astronomii le-au descoperit in ultimii ani.
Dupa cum puteti observa, ontologia (Star Wars vs corpurile ceresti) si taxonomiile (planetele din Star Wars vs exoplanetele) stabilesc contextul si ajuta la stabilirea diferentelor dintre entitatile similare.
Ontologia, taxonomia si contextul conduc la semnificatie
Cu cat definim mai bine ontologia site-ului nostru, cu cat ii structuram mai bine taxonomia si cu cat oferim un context mai bun elementelor sale, cu atat vom explica mai bine semnificatia site-ului nostru – atat utilizatorilor, cat si motorului Google.
Starwars.com exceleaza si in acest sens.
De exemplu, daca analizam modul in care structureaza o pagina precum cea despre luptatorii TIE (TIE fighters), observam ca orice tip de continut este utilizat pentru a explica ce este un luptator TIE.
1. Descriere generică (text);
2. Aparitii ale luptatorilor TIE in filmele Star Wars (link-uri interne cu text ancora optimizat);
3. Afilieri (link-uri interne cu text ancora optimizat);
4. Dimensiuni (text);
5. Videoclipuri;
6. Galerie foto;
7. Placa de sunet (Citate celebre ale personajelor; in acest caz, ar fi clasicul sunet “zzzzeeewww”, pe care multi dintre noi l-au folosit ca ton de apel pentru vechile telefoane Nokia);
8. Citate (text);
9. Istoric (un articol substantial cu text, imagini si legaturi catre alte documente);
10. Subiecte asociate sau asemanatoare (plus link-uri interne).
In cazul unor personaje precum Darth Vader, informatiile pot fi chiar mai substantiale.
Eficacitatea arhitecturii informatiilor site-ului Star Wars (plus autoritatea sa) este de asa natura, incat banca sa de date (DataBank) este una dintre putinele surse non-Wikidata / non-Wikipedia pe care Google le utilizeaza ca sursa pentru Graficul de cunostinte (Knowledge Graph).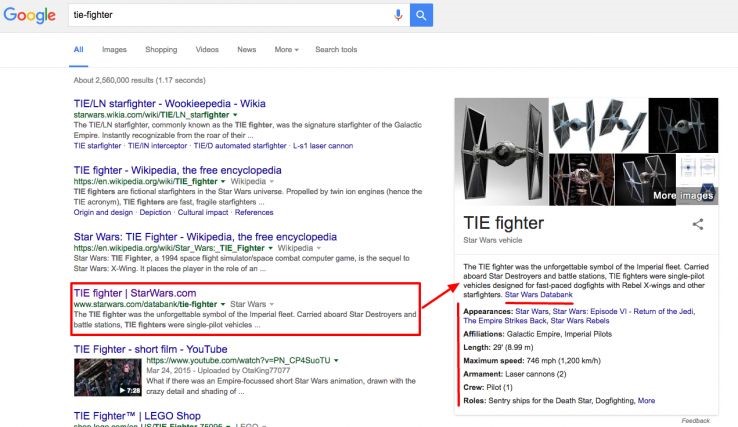
Ce instrument putem folosi pentru a optimiza din punct de vedere semantic structura unui site web?
Exista, de fapt, mai multe instrumente pe care le putem folosi pentru a optimiza din punct de vedere semantic arhitectura de informatii a unui site web.
Knowledge Graph Search API
Primul dintre aceste instrumente este Knowledge Graph Search API intrucat, folosind acest instrument, putem obtine o lista ordonata, un clasament, al entitatilor care corespund criteriilor date.
Acest lucru ne poate ajuta sa definim mai bine subiectele aferente unui domeniu (ontologie) si poate oferi idei despre modul de structurare a unui site web sau modul de structurare a oricarui tip de document web.
RelFinder
Un al doilea instrument pe care il putem folosi este RelFinder, care este unul dintre putinele instrumente gratuite pentru cercetarea entitatilor.
Dupa cum se poate vedea in captura dekstop de mai jos, RelFinder se bazeaza pe Wikipedia. Este destul de simplu de utilizat:
1. Alegeti entitatea dumneavoastra principala (de exemplu, Star Wars);
2. Alegeti entitatea cu care doriti sa vedeti conexiuni (de exemplu: Star Wars Episode IV: A New Hope / Star Wars Episodul IV: O noua speranta);
3. Faceti click pe Find Relations (Gasiti legaturi);
RelFinder va detecta entitatile care au legatura cu ambii (George Lucas sau Marcia Lucas), proprietetile care ii diferentiaza (spre exemplu: George Lucas in calitate de regizor, producator si scriitor) si cele concrete (spre exemplu: sabiile laser ca o entitate legata de Star Wars, vazuta prima data in episodul al 4-lea).
Screencast RelFinder: https://www.youtube.com/watch?v=05zGixmcXPA
RelFinder este foarte util in situatiile in care trebuie sa facem cercetarea entitatilor pe o scara mica, cum ar fi atunci cand pregatim un fragment de continut sau un site web mic.
Cu toate acestea, in cazul in care trebuie sa facem cercetarea entitatilor pe o scara mai mare, este mult mai bine sa ne bazam pe urmatoarele instrumente:
AlchemyAPI si alte instrumente:
AlchemyAPI, care a fost achizitionat de catre IBM anul trecut, foloseste invatarea automata si profunda pentru a realiza rocesarea limbajului natural, analiza de text semantic si viziunea computerizata.
AlchemyAPI, care ofera un cod pentru o perioada de proba de 30 de zile, se bazeaza pe tehnologia Watson; aceasta ne permite sa extragem o cantitate mare de informatii din text, cu concepte, entitati, cuvinte cheie si taxonomie, oferite in mod implicit.
Resurse despre AlchemyAPI
• Ghid pentru incepatori;
• Ghid de referinta AlchemyLanguage;
• Cum sa utilizati AlchemyAPI pentru extragerea entitatilor dintr-un document – un istoric de caz.
Alte instrumente care ne permit sa facem extractia entitatilor si analiza semantica pe o scara mare sunt:
• TextRazor;
• Open Calais;
• Aylien.
• SeoAccounts.net
Semantica lexicala
Asa cum am mai mentionat, semantica lexicala este acea ramura a semanticii care studiaza semnificatia cuvintelor si legaturile dintre acestea.
In contextul cautarii semantice, acest domeniu este de obicei definit drept cercetarea cuvintelor cheie si cercetare de actualitate.
Aici, pe MOZ, gasiti mai multe videoclipuri pe acest subiect:
• Este posibil ca expertii SEO sa nu mai fie ingrijorati in ceea ce priveste cuvintele cheie si sa se concentreze, pur si simplu, pe subiecte?;
• Utilizarea, in procesul dumneavoastra de SEO, a subiectelor conexe si a cuvintelor cheie conectate din punct de vedere semantic;
• De ce nu putem realiza cercetarea cuvintelor cheie ca in 2010;
• Invatati motorul Google despre entitatile dumneavoastra utilizand hub-uri de actualitate.
Cum putem desfasura o cercetare a cuvintelor cheie si o cercetare de actualitate concentrata pe semantica?
In ciuda recentei sale actualizari, Planificatorul de cuvinte cheie (Keyword Planner) inca mai poate fi util pentru efectuarea unei cercetari a cuvintelor cheie si a unei cercetari de actualitate concentrata pe semantica.
De fapt, aceasta actualizare ar putea fi chiar considerata ca o alegere logica, dintr-un punct de vedere al cautarii semantice.
Termeni precum “PPC” si “pay-per-click” sunt sinonime si, chiar daca fiecare are cu siguranta un volum de cautare diferit, este evident modul in care Google prezinta doua pagini cu rezultate foarte asemanatoare daca vom cauta unul dintre acesti doi termeni, mai ales daca istoricul cautarii prezinta deja un model al cautarilor asociate cu SEM (marketing pentru motorul de cautare).
Totusi, aceasta diminuare a datelor despre cuvintele cheie este mai putin utila pentru expertii SEO, in sensul ca duce la ingreunarea procesului de prognozare si prioritizare a cuvintelor cheie care trebuiesc vizate.
Acest lucru este valabil mai ales atunci cand cautam termeni scurti, populari si simpli (head terms), intrucat amplifica o problema pe care Planificatorul de cuvinte cheie (Keyword Planner) o are: mai exact, Planificatorul combina cuvinte cheie derivate care, desi au la baza cuvantul cheie pe care il cautam, nu au nimic in comun cu acesta, intrucat au cu totul o alta semnificatie si vizeaza subiecte complet diferite.
Cu toate acestea (iar acasta este un sfat care va poate ajuta sa deveniti profesionisti), exista o modalitate de a descoperi cel mai util cuvant cheie, chiar si atunci cand toate au acelasi volum de cautare: suma pe care agentii de publicitate o liciteaza pentru respectivul cuvant. Aveti incredere in piata!
Daca doriti sa aflati mai multe despre schimbarile recente suferite de Planificatorul de cuvinte cheie, consultati acest articol, scris de catre Bill Slawski.
Keyword Planner (Planificatorul de cuvinte cheie) pentru cautarea semantica
Sa presupunem ca vrem sa cream un site despre sabiile laser din Star Wars (da, sunt dependent de Star Wars).
Ceea ce putem face este urmatorul lucru: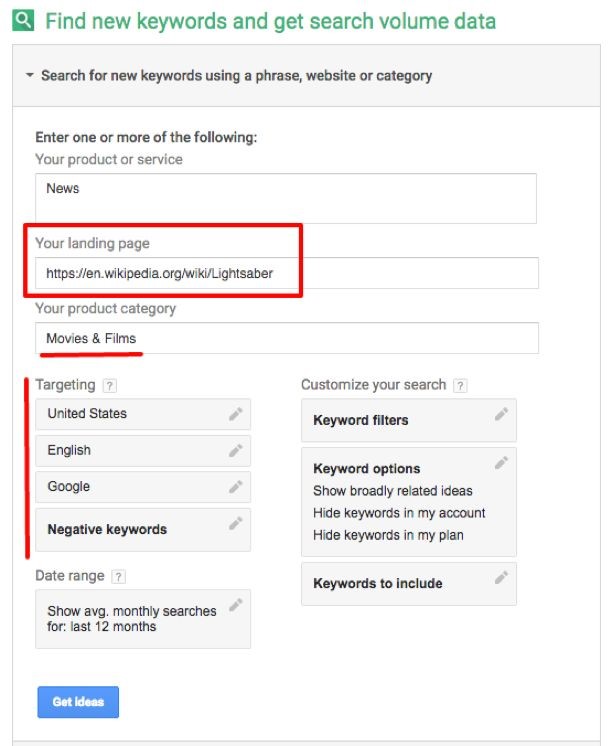
1. Deschideti Keyword Planner (Planificatorul de cuvinte cheie) / Find new Keywords (Gasiti cuvinte cheie noi) si obtineti informatii despre volumul cautarilor;
2. Descrieti produsul sau serviciul (in rubrica “News” din captura de mai sus);
3. Utilizati pagina Wikipedia despre sabii laser ca pagina de destinatie (in cazul in care site-ul dumneavoastra este in limba spaniola, este recomandat sa utilizati versiunea in limba spaniola a Wikipedia).
4. Indicati categoria produsului dumneavoastra (de exemplu, Movies & Films din captura de mai sus);
5. Definiti obiectivul si, in cele din urma, indicati cuvintele cheie negative;
6. Faceti clic pe Get Ideas (“Obtineti Idei”).
Google ne va oferi aceste grupuri de anunturi ca rezultate:
Grupurile de anunturi (Ad Groups) sunt o colectie de cuvinte cheie asociate semantic, foarte utile pentru:
1. Individualizarea subiectelor;
2. Crearea unui dictionar de cuvinte cheie care poate fi oferit scriitorilor pentru text, text care va fi atat natural, cat si consistent din punct de vedere semantic.
In acest caz, retineti ca Planificatorul de cuvinte cheie ne permite sa realizam si alte tipuri de analize, precum cercetarea modului in care cuvintele cheie / grupurile de anunturi descoperite sunt utilizate de dispozitiv sau de locatie. Aceasta informatie este utila pentru intelegerea contextului publicului nostru.
Daca aveti una sau cateva entitati pentru care doriti sa descoperiti subiecte si cuvinte cheie grupate, este suficient sa lucrati direct in Keyword Planner si sa exportati totul in Google Sheets sau intr-un fisier Excel.
Cu toate acestea, atunci cand aveti de analizat zeci sau sute de entitati, este mult mai bine sa utilizati Adwords API sau un instrument precum SEO Powersuite, care va permite sa faceti cercetarea cuvintelor cheie urmand metoda pe care am descris-o mai sus.
Google Suggest, Related Searches si Moz Keyword Explorer
In paralel cu utilizarea Planificatorului de cuvinte cheie, putem folosi Google Suggest si Related Searches. Nu doar pentru a individualiza subiectele pe care oamenii le cauta si pentru a scrie, apoi, pe blog, o postare sau o pagina de destinatie despre ele, ci pentru reafirmarea si perfectionarea arhitecturii site-ului nostru.
Revenind la exemplul unui site sau al unei sectiuni specializate in lightsabers (sabii laser), daca ne uitam la Google Suggest putem observa ca “lightsaber replica” (“imitatie sabie laser”) este una dintre sugestii.
Mai mult decat atat, printre cautarile similare pentru “lightsaber”, vom vedea din nou “lightsaber replica”, ceea ce este un semnal clar al relevantei sale pentru cuvantul cheie “lightsaber”.
In cele din urma, putem face click pe aceasta sugestie si vom descoperi cautari asociate pentru “lightsaber replica”, creand, astfel, ceea ce numesc eu “peisajul cautarilor” la un subiect.
Modelul de mai sus nu este scalabil daca avem multe entitati de analizat. In acest caz, un instrument precum Moz Keyword Explorer poate fi extrem de util, multumita optiunilor pe care le ofera, dupa cum se poate observa in captura de mai jos: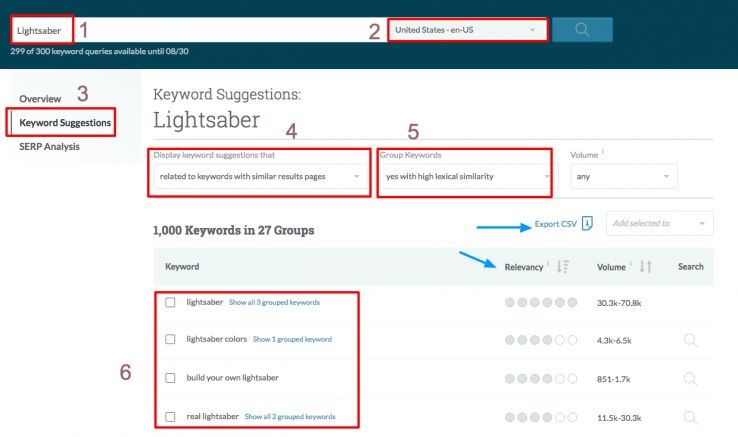
Alte surse de cercetare a cuvintelor cheie si cercetare de actualitate
Recent, Powerreviews.com a publicat rezultatele sondajului care prezinta modul in care utilizatorii de Internet au tendinta de a prefera Amazon in detrimentul Google atunci cand vine vorba de cautarea de informatii despre un produs (38% fata de 35%).
Asadar, de ce sa nu folosim Amazon pentru a efectua o cercetare a cuvintelor cheie si o cercetare de actualitate, mai ales daca o efectuam pentru site-uri de comert electronic sau pentru fazele MOFU (atunci cand s-a trecut de etapa de cercetare si se evalueaza diversele optiuni) si BOFU (etapa in care leadurile leadurile s-au informat, au comparat si sunt pregatite sa achizitioneze un anumit produs) ale calatoriei clientilor nostri?
Putem folosi Amazon Suggest:
Sau putem folosi un instrument gratuit, cum ar fi Amazon Keyword Tool, lansat de SISTRIX.
Functia Suggest, totusi, este prezenta in (aproape) fiecare site care are o caseta de cautare (poate chiar in propriul dumneavoastra site, daca este bine implementat!)
Ceea ce inseamna ca, daca suntem in cautare de subiecte mai mainstream si top-of- the-funnel (etapa in care vizitatorii care au ajuns pe site-ul dumneavoastra fie pentru ca ati folosit o strategie excelenta de content marketing, fie datorita eforturilor de SEO, fie datorita planului de social media), putem folosi sugestiile retelelor sociale, cum ar fi Pinterest (de exemplu, explorati universul voluptos al “torturilor lightsaber” (“lightsaber cakes”) si al subiectelor conexe.)
In acest caz, Pinterest este o adevarata mina de aur a cercetarii de actualitate, multumita sistemului sau de etichetare:
Pe pagina
Odata ce am definit arhitectura, subiectele, si odata ce am pregatit dictionarele de cuvinte cheie, putem lucra, in cele din urma, la fateta / aspectul pe pagina a muncii noastre.
Detaliile cu privire la totalitatea actiunilor de optimizare aduse paginii vor fi tratate intr-o alta postare, asa ca pur si simplu va voi recomanda sa cititi acest articol foarte actual, scris de Cyrus Shepard.
Cea mai buna modalitate de a clasa optimizarea cautarii semantice a unui text scris o reprezinta utilizarea analizei TF-IDF, oferita de site-uri precum OnPage.org (care ofera, de asemenea, un ghid clar cu privire la avantajele si dezavantajele analizei TF-IDF).
Este important de retinut faptul ca analiza TF-IDF poate fi, de asemenea, utilizata pentru realizarea unei analize competitive de cautare semantica si pentru a descoperi dictionarele de cuvinte cheie utilizate de catre competitorii nostri.
Comportamentul utilizatorului / Semiotica si context

La inceputul acestui articol, am explicat modul in care Google investeste puternic in a intelege mai bine semnificatia documentelor pe care le acceseaza cu crawlere, astfel incat sa raspunda mai bine interogarilor efectuate de catre utilizatori.
Semantica (si implicit cautarea semantica) reprezinta doar unul dintre pilonii pe care Google se bazeaza in acest efort imens.
Celalalt pilon consta in intelegerea comportamentelor de cautare a utilizatorilor si a contextului utilizatorilor care efectueaza o cautare.
Comportamentul de cautare al utilizatorului
Recent, Larry Kim distribuit doua postari bazate pe experimentele pe care le-a facut, demonstrand teoria sa conform careia RankBrain este despre factori precum CTR (rata de click) si timpul de stationare.
Desi aceste articole sunt extrem de discutabile, prezinta informatii interesante cu date originale si confirma faptul ca alte teste efectuate in trecut, asa-numitele semnale ale utilizatorilor (CTR si timpul de stationare) nu sunt direct legate de RankBrain ci, in schimb, sunt legate de comportamentele de cautare ale utilizatorilor si de cautarea personalizata.
Retineti, totusi, ca afirmatia mea de mai sus ar trebui sa fie considerata drept o teorie personala, intrucat Google insusi nu intelege pe deplin cum functioneaza RankBrain.
AJ Kohn, Danny Sullivan si David Harry au scris articole suplimentare foarte interesante despre RankBrain, in cazul in care doriti o aprofundare a informatiilor (ca fapt divers, am tratat si eu acelasi subiect, aici, pe MOZ).
Chiar daca RankBrain poate fi inclus in peisajul cautarii semantice datorita utilizarii tehnologiei Word2Vec, mi se pare mai indicat sa ne concentram pe modul in care Google poate utiliza comportamentele de cautare ale utilizatorilor, pentru a intelege mai bine relevanta documentelor parsate si indexate.
Click-through rate (rata de click)
Inca de cand Rand Fishkin si-a prezentat, in urma cu mai mult de doi ani, teoria – sustinuta de teste – conform careia Google utilizeaza CTR (rata de click) ca factor de ranking, s-a scris mult despre importanta ratei de click.
Buna judecata sugereaza ca, daca oamenii fac click mai des pe o sugestie de cautare mai des decat pe alta care, probabil, se claseaza pe o pozitie mai buna in topul rezultatelor cautarii, atunci Google ar trebui sa ia in considerare semnalul acelor utilizatori si, in cele din urma, sa ridice pozitia, in clasamentul rezultatelor cautarii, a paginii care primeste in mod constant o mai mare rata de click.
Cu toate acestea, buna judecata nu este atat de usor de aplicat atunci cand vine vorba de motoarele de cautare, iar angajatii Google au declarat in mod repetat ca nu folosesc CTR (rata de click) ca si factor de ranking (a se vedea aici si aici).
Si, desi Google a dezvoltat acum mult timp un sistem de detectare a fraudei de click-uri pentru Adwords, inca nu este clar daca ar putea sa il masoare pentru cautarea organica.
Pe de alta parte – permiteti-mi sa fiu un pic conspiranoic – daca CTR nu este deloc importanta, atunci de ce Google a schimbat pixelii titlului tag si meta descrierii? Doar pentru un “design mai bun”?
Dar, dupa cum Eric Enge a scris in aceasta postare, unul dintre putinele lucruri pe care le stim este ca Google a depus un brevet (Modificarea clasamentului rezultatelor cautarii bazat pe un element temporal al feedback-ului utilizatorului, mai 2015) despre rata de click – CTR. Este cert faptul ca utilizarea CTR in mediile de testare pentru a calcula mai bine valoarea si gradul altor factori si – acest lucru este mai speculativ – poate da o importanta mai puternica ratei de click din acele subseturi de cuvinte cheie care exprima in mod clar o nevoie QDF (Query Deserves Freshness / Interogare merita prospetime).
Ceea ce este mai putin dezbatut este importanta pe care CTR o are in cautarea personalizata, intrucat stim ca Google tinde sa “picteze”, sa “impodobeasca” o pagina cu rezultate personalizata pentru fiecare dintre noi, in functie de istoricul cautarilor dar si de istoricul personal al ratei de click. Acestea sunt esentiale in a ajuta Google sa determine care pagini cu rezultate vor fi cel mai utile pentru noi.
De exemplu:
1. Daca vom cauta ceva pentru prima data si
2. pentru respectiva cautare nu avem un istoric al cautarilor (sau istoricul nu este suficient pentru a declansa rezultatele personalizate) si
3. cautarea prezinta entitati ambigue (de exemplu: “Amber”),
4. atunci numai datorita ratei de click personale si datorita istoricului personal al cautarilor Google va determina care dintre rezultatele cautarii asociate cu o anumita entitate vor fi sau nu afisate (amber cu sens de piatra / chihlimbar, Amber Rose sau Amber Alerts…)
In cele din urma, chiar daca Google nu utilizeaza CTR ca factor de ranking, acest lucru nu inseamna ca nu este o valoare importanta si un semnal important intr-o campanie SEO. Avem ani de experienta si sute de teste care dovedesc cat de importanta este optimizarea informatiilor relevante sub cautari / search snippets (si acum Rich Cards, care apar sub forma unor informații suplimentare despre pagina respectiva) cu utilizarea adecvata a datelor structurate, cu scopul de a castiga mai mult trafic organic, chiar daca ne clasam pe o pozitie mai joasa mai decat competitorii nostri.
Timpul vizionarii
Valorile ridicate ale ratei de click sunt total inutile daca paginile pe care aterizeaza vizitatorii nostri nu se ridica la inaltimea calitatii fragmentelor recomandate.
Acest lucru este similar cu diferenta dintre un clickbait si un titlu convingator. Primul va motiva utilizatorii sa se intoarca la pagina rezultatelor cautarii, iar cel de-al doilea, in schimb, va capta interesul vizitatorilor.
Capacitatea unui site de a-si pastra utilizatorii este ceea ce numim de obicei timp de stationare, dar ceea ce Google defineste drept timp de vizionare in brevetul Watch Time-Based Ranking (Ranking bazat pe timpul de stationare) din martie 2013.
Acest brevet este, de obicei, citat in legatura cu videoclipurile, intrucat brevetul in sine foloseste video ca exemplu de continut, dar Google nu ii restrictioneaza definitia doar pentru videoclipuri:
In general, “timpul de vizionare” se refera la timpul total pe care un utilizator il petrece urmarind un videoclip. Cu toate acestea, timpul de vizionare poate fi calculat si utilizat pentru a clasifica alte tipuri de continut pe baza unei cantitati de timp pe care un utilizator o petrece vizionand continutul.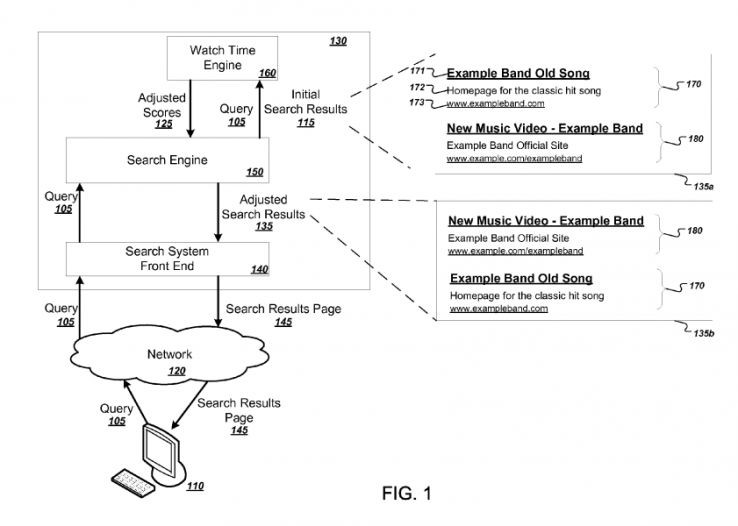
Timpul de vizionare este, intr-adevar, un semnal al utilizatorului mult mai util decat CTR (rata de click) in intelegerea calitatii unui document web si a continutului acestuia.
Sunteti sceptici si nu ma credeti? Atunci, aveti incredere in Facebook, care foloseste, de asemenea, timpul de vizionare in algoritmul sau de news feed:
Am invatat ca timpul pe care oamenii aleg sa il petreaca citind sau vizionand un continut pe care au dat click din News Feed este un semnal important ca povesea le-a captat interesul.
Adaugam un alt factor de clasare a continutului din News Feed, astfel incat vom putea anticipa cat timp petreceti analizand un articol de pe browser-ul mobil Facebook sau un articol instant dupa ce ati făcut click din News Feed. Aceasta actualizare a clasamentului va lua in considerare cat de mare este probabilitatea de a face click pe un articol pentru ca, mai apoi, sa petreceti timp citindu-l. Nu vom calcula timpul de incarcare, ci vom fi lua in considerare timpul petrecut citind si vizionand continutul, odata ce acesta s-a incarcat complet. Vom analiza, de asemenea, si timpul pe care utilizatorul il petrece intr-un anumit prag, astfel incat articolele lungi sa nu aiba parte, din greseala, de un tratament preferential.
Aceasta schimbare ne va ajuta sa intelegem mai bine care sunt articolele care v-ar putea interesa, bazandu-ne pe timpul pe care dumneavoastra si alti vizitatori il petreceti citindu-le, astfel incat sansele ca in News Feed sa apara povesti si articole care va starnesc interesul vor fi mult mai mari.
Contextul si importanta cautarii personalizate
De obicei, glumesc si spun ca cea mai mare greseala pe care o membrii unei bande de spargatori de banci o pot face este sa-si ia cu ei smartphone-urile. Ar fi destul de simplu sa facem investigatii de tip PreCrime (pre-crima) doar prin verificarea tabelului activitatilor membrilor bandei, care include istoricul locatiilor acestora pe Google Maps.
Pentru a-si indeplini misiunea de a le oferi cele mai bune raspunsuri utilizatorilor sai, Google nu trebuie sa inteleaga numai documentele web pe care le acceseaza cu crawlere astfel incat sa le indexeze (clasifice) in mod corespunzator; mai mult, nu trebuie numai sa-si imbunatateasca proprii factori de ranking (luand în considerare semnalele pe care utilizatorii le dau in timpul sesiunilor de cautare), ci trebuie sa inteleaga, de asemenea, contextul in care utilizatorii efectueaza o cautare.
Iata ce stie Google despre noi: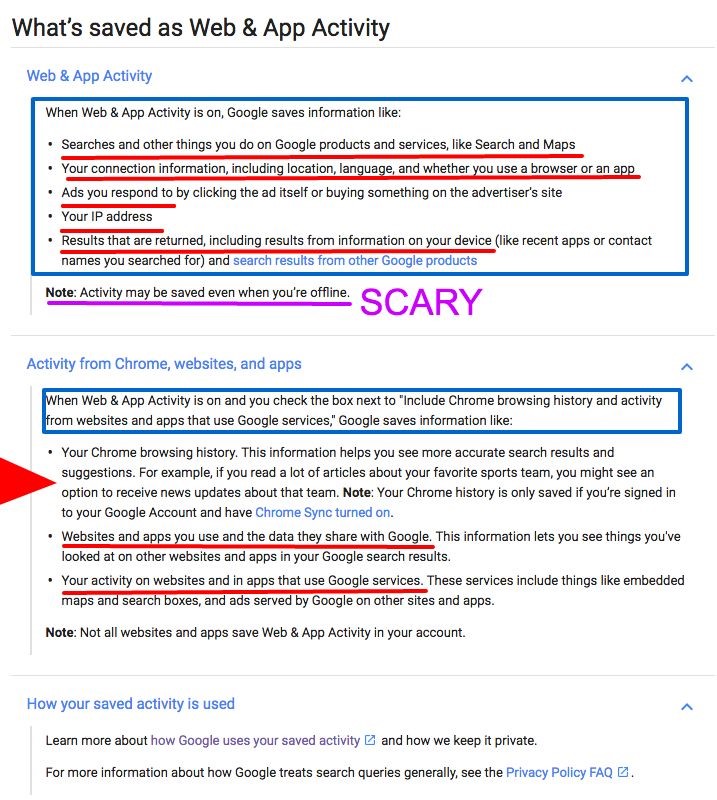
Din cauza acestei nevoi imperioase de a intelege contextul nostru, Google a angajat, in anul 2013, intreaga echipa Behav.io.
Behav.io, daca nu stiati deja, a fost o companie care a dezvoltat un software de testare alfa bazat pe propriul sau framework open sorce, Funf (inca exista), al carui scop era de a inregistra si de a analiza datele carora smartphone-urile le tin evidenta: locatia, viteza, dispozitivele si retelele din apropiere, activitatea efectuata cu ajutorul telefonului, nivelul de zgomot, iar lista poate continua.
Toate aceste informatii sunt necesare pentru a intelege mai bine aspectele implicite ale unei interogari, mai ales daca respectiva interogare este facuta de pe un smartphone si / sau prin intermediul functiei de cautarea vocala, dar si pentru a procesa mai bine ceea ce Tom Anthony si Will Critchlow definesc drept “interogari compuse”.
Cu toate acestea, cautarea personalizata este determinata si de catre (din nou) cautarea entitatilor, in special de catre entitatile de cautare.
Relatia dintre entitatile de cautare creeaza un “scor de probabilitate”, care poate determina daca un document web este afisat / prezentat sau nu pe o pagina determinata a rezultatelor cautarii.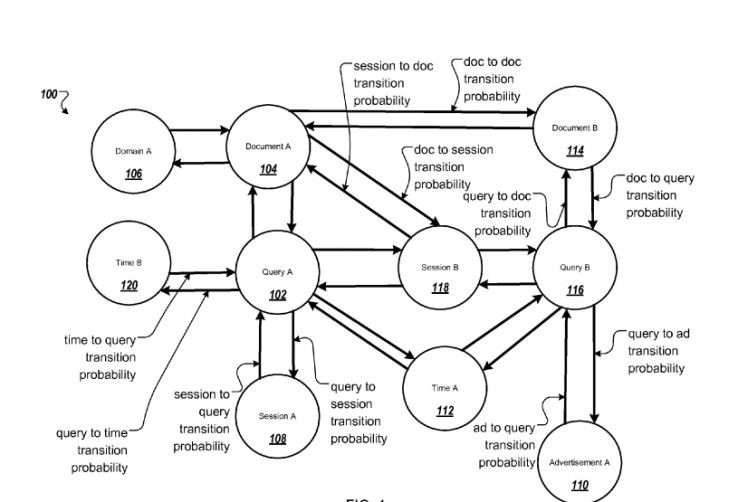
De exemplu, sa presupunem ca un utilizator efectueaza o cautare cu privire la un subiect (de exemplu: Wookies) pentru care nu a facut niciodata click pe un fragment recomandat (search snippet) extras de pe site-ul nostru, ci pe un alt fragment care continea informatii despre acelasi subiect (cum ar fi Wookieepedia) si care facea legatura catre o pagina de pe site-ul nostru care trateaza acelasi subiect (de exemplu: “Cum sa distingem un wookiee de altul?”)
Aceste link-uri – in special textele lor ancora – ajuta site-ul si pagina noastra sa castige un scor de probabilitate mai mare decat un site concurent catre care aceste site-uri prezente in istoricul cautarilor utilizatorului nu fac trimitere.
Asta inseamna ca va exista o probabilitate mai mare ca pagina noastra sa apara in pagina personalizata cu rezultatele cautarii a respectivului utilizator decat paginile competitorilor nostri.
Probabil va intrebati: care este rostul concret al acestui brevet?
Link building-ul (construirea de link-uri) si castigul de link-uri nu au murit deloc, intrucat sunt relevante nu numai pentru Graficul Link-urilor (Link Graph), ci si pentru cautarea entitatilor. Cu alte cuvinte, construirea de link-uri inseamna si cautare semantica.
Importanta branding-ului si a marketingului offline pentru SEO
Una dintre cele mai frecvente plangeri pe care expertii SEO le au cu privire la Google este legata de modul in care compania favorizeaza brandurile.
Problema reala, insa, ar trebui sa fie urmatoarea: “De ce nu muncesti ca sa devii un brand?”
Retineti! Nu vorbesc aici despre “viziune”, “misiune” si “valori”, ci vorbesc pur si simplu despre semantica.
Pe tot parcursul acestui articol am vorbit despre entitati (cele numite si cele de cautare), am mentionat despre Word2Vec (vectorii sunt “mari cantitati de limbaj scris incorporate in entitati matematice”), am vorbit despre semantica lexicala, sens, ontologie, cautare personalizata si subiecte implicite precum competitie si baza de cunostinte.
Branding-ul este in stransa legatura cu toate aceste lucruri.
Voi incerca sa explic cele spune printr-un exemplu foarte personal.
In luna mai a anului trecut, in Valencia, am debutat ca organizator de conferinte cu The Inbounder.
Una dintre problemele cu care m-am confruntat in procesul de promovare a evenimentului a fost ca “inbounder”, denumire pe care am considerat-o potrivita pentru un eveniment care vizeaza adeptii marketingului de tip inbound (Inbound Marketing este modalitatea de a aduce in procesul de vanzare clienti potentiali calificati) este, de asemenea, un termen folosit in baschet.
Problema era evidenta: ce sa fac in asa fel incat Google sa inteleaga ca The Inbounder nu era despre baschet, ci despre marketing digital?
Strategia pe care am urmat-o de la bun inceput a fost sa lucram la branding-ul evenimentului.
Am facut urmatoarele lucruri:
• Am organizat evenimente locale mici, astfel incat:
o sa dezvoltam prezenta in ziarele locale on-line si off-line, o metoda care, de asemenea, obliga specialistii in marketing sa caute pe Google despre eveniment folosind cuvinte cheie ce tin de brand (spre exemplu: “Conferinta Inbounder”, “Conferinta pentru inbound marketing <Inbounder>”, si altele) si
o sa faca click pe fragmentele noastre recomandate, afisate in pagina cu rezultatele cautarii, activand, in acest mod, cautarea personalizata.
• Am lucrat cu influentatori (vorbitorii in persoana) pentru a declansa cautarile de brand si a directiona trafic (retineti: Chrome stocheaza fiecare URL pe care il vizitam);
• Ne-am mobilizat si am scris guest post-uri despre eveniment pe site-urile vizitate de catre publicul nostru (si inregistrate in istoricul cautarii).
Rezultatul? “The Inbounder” ocupa, la ora actuala, prima pagina a rezultatelor generate de motorul de cautare Google pentru numele sau de brand si, mai important, in termeni semantici, Google prezinta evenimentele Inbounder ca si cautari sugerate si similare. Il asociaza cu toate cautarile pe care le puteam dori:
Un alt exemplu este Trivago si campaniile sale globale de publicitate TV:
Cei de la Trivago au fost foarte isteti folosind constant “Trivago” si “hotel” in aceeasi fraza. Ba chiar si motto-ul lor se bazeaza pe aceste cuvinte: “Hotel? Trivago”.
Acesta este un simplu truc psihologic pentru a crea asocieri de cuvinte.
Ca rezultat, oamenii au cautat pe Google “hotel Trivago” (sau “Trivago hotel”), mai ales imediat dupa ce anunturile au fost difuzate: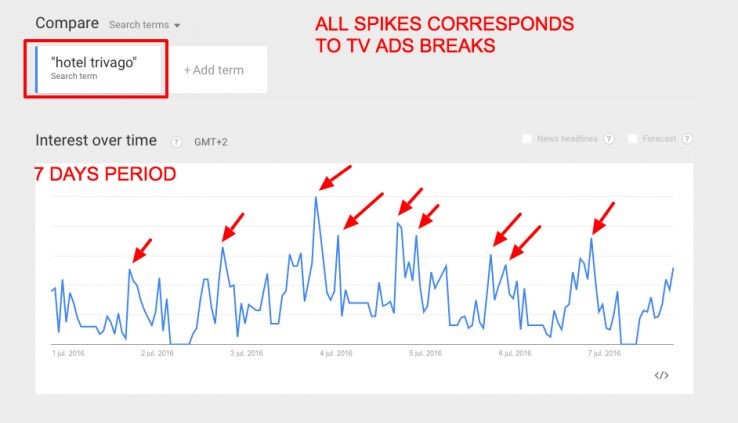
Unul dintre rezultate este ca, acum, Google sugereaza “hotel Trivago” cand incepem sa tastam “hotel” si, la fel ca in cazul Inbounder, prezinta “hotel Trivago” ca si cautare asociata: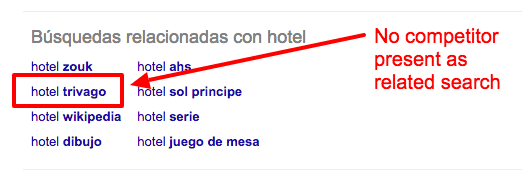
Treziti-va, experti SEO! Un Google nou nout este aici!
Da, este. Si totul pentru o mai buna intelegere a documentelor web si a interogarilor, in scopul de a oferi cele mai bune raspunsuri utilizatorilor sai (si a face si bani intre timp).
Pentru a atinge acest obiectiv, pentru a deveni in mod ideal mult-doritul “calculator Star Trek”, Google investeste bani, oameni si eforturi in invatarea profunda si automata, retele neuronale, semantica, comportamentul de cautare, analiza contextului si cautarea personalizata.
Retineti, SEO nu mai este doar despre “200 de factori de ranking”. SEO este despre efortul de a face ca site-urile noastre sa devina sursele pe care Google sa le foloseasca pentru a raspunde interogarilor.
Tocmai din acest motiv cautarea semantica este de o importanta majora; nu este doar ceva ce merita atentia catorva tocilari pasionati de lingvistica, informatica si brevete.
Lucrati la optimizarea parsarii si indexarii, puneti serios in aplicare cautarea semantica in strategia dumneavoastra de SEO, profitati de oportunitatile pe care vi le ofera cautarea personalizata si puneti mereu utilizatorii in centrul a tot ceea ce faceti.
Procedand astfel, va veti asigura succesul pentru anii urmatori, atat prin intermediul cautarii clasice cat si prin Google Assistant si Google Now.